8 Crucial Insights About Kubernetes PSI Metrics Now Stable in v1.36
Pressure Stall Information (PSI) has quietly transformed how we detect resource saturation in Linux systems. Originally hitting the kernel in 2018, PSI offers a more nuanced view than traditional utilization numbers—tracking exactly how much time tasks spend stalled due to CPU, memory, or I/O contention. Now, with Kubernetes v1.36 officially promoting PSI metrics to General Availability, cluster operators across the ecosystem gain a production-ready window into node, pod, and container-level pressure. In this article, we break down the eight most important things you need to know about this milestone release, from the core concepts to the rigorous performance testing that proved it safe for real-world loads.
1. What PSI Actually Measures (and Why It Matters)
PSI doesn't just report raw utilization percentages. Instead, it captures the real cost of resource contention: the time that tasks are forced to wait. When a CPU is busy at 80% but a critical thread experiences severe scheduling latency, standard metrics miss the pain. PSI fills that gap by recording cumulative stalled time and exposed moving averages. This makes it invaluable for identifying silent resource starvation before it triggers an outage. In a Kubernetes context, PSI gives you a more truthful picture of how your workloads are actually experiencing the underlying hardware—and that changes how you tune, scale, and debug.
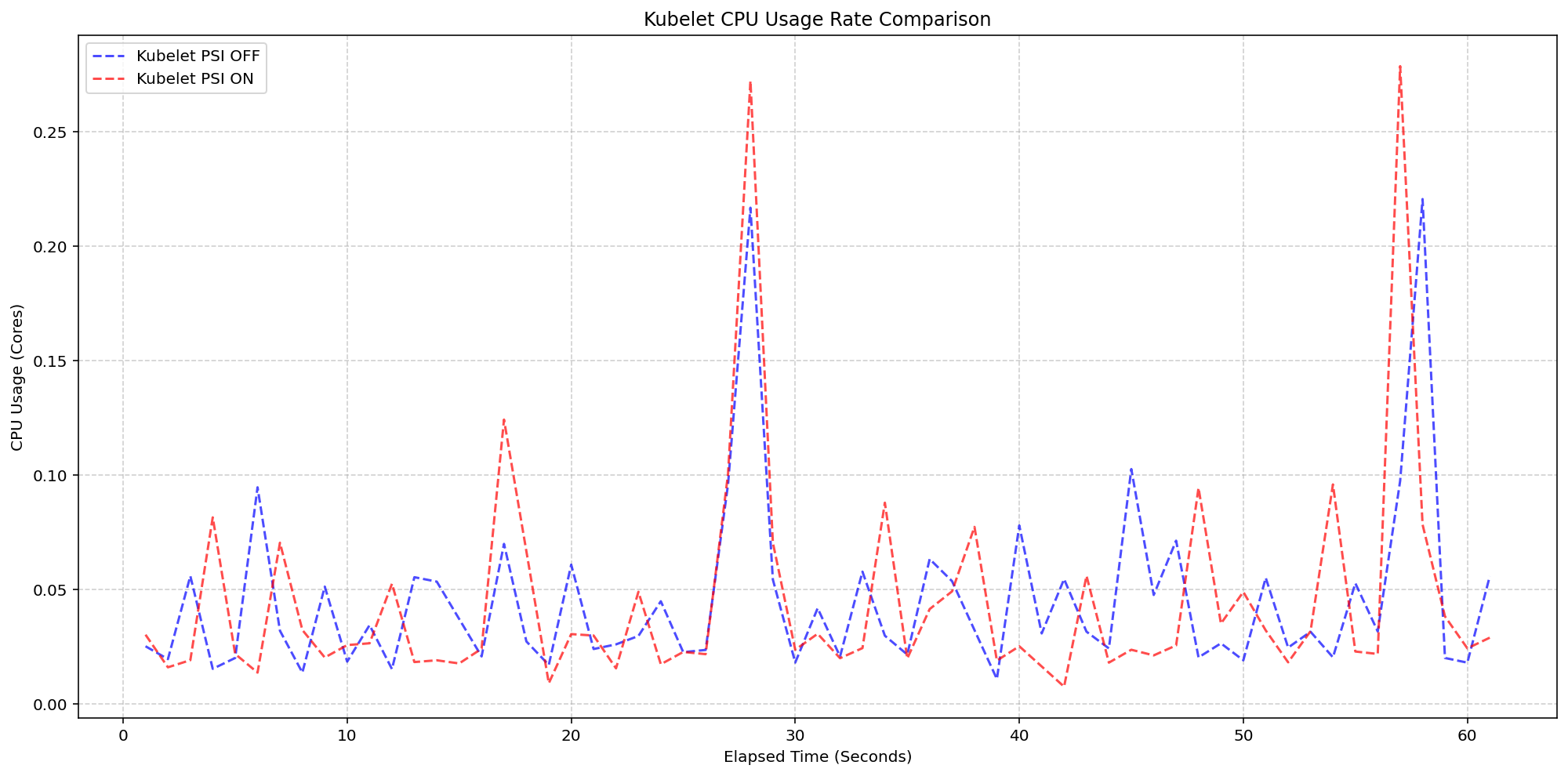
2. From Experiment to GA: What Graduation Means
The graduation of PSI metrics to GA in Kubernetes v1.36 signals that the feature has passed rigorous stability, performance, and API review gates. It's no longer behind a feature gate (KubeletPSI) and is considered production-ready across upstream-supported architectures. For operators, this means you can rely on PSI data as a first-class citizen in monitoring pipelines, without worrying about breaking changes or instability. The GA status also encourages tooling vendors and open-source projects to integrate PSI signals more deeply, driving a richer ecosystem around pressure-based alerting and autoscaling.
3. Beyond Utilization: The Two Key PSI Metrics
PSI exposes two primary data forms: cumulative totals and moving averages. Cumulative totals sum up all stalled time since boot across CPU, memory, and I/O—raw counters that let you compute rates over custom windows. Moving averages smooth that data over 10s, 60s, and 300s windows, helping you distinguish between transient spikes and persistent pressure. The Kubernetes API exposes these per-container, per-pod, and per-node through the metrics endpoint. That layered view is what makes PSI so powerful: you can pinpoint whether contention is happening at the node level or inside a specific cgroup.
4. Why Performance Testing Was Critical for GA
A common worry with any new telemetry feature is overhead: will collecting and exposing PSI metrics consume too much CPU or memory, especially on already-stressed nodes? The SIG Node team took this seriously. They designed a series of benchmark experiments using high-density workloads (80+ pods per node) across different machine types. The goal was to isolate two potential sources of overhead: the Kubelet's own polling logic (Kubelet overhead) and the kernel's PSI tracking itself (kernel overhead). Only by proving both were negligible could the feature graduate.
5. Two Scenarios That Isolated the Real Cost
To measure overhead precisely, the team ran two parallel comparisons. Scenario 1 compared clusters with kernel PSI enabled in both but with the Kubelet PSI feature gate toggled on vs. off—isolating Kubelet's cost. Scenario 2 compared clusters where kernel PSI was disabled but the Kubelet feature was on, against a baseline with both enabled. This separation ensured that any extra CPU usage could be attributed to the correct layer. The results, published in the Kubernetes enhancement proposal, gave clear evidence that neither layer added meaningful pressure to production nodes.
6. Kubelet Overhead: Nearly Invisible on Real Nodes
For Scenario 1, testing on 4-core machines showed that the Kubelet's PSI collection logic had virtually no measurable impact on CPU usage. The graph comparing Kubelet CPU rate over time between PSI-enabled and PSI-disabled clusters revealed synchronized bursts of identical magnitude and frequency. The feature consumed roughly 0.1 cores—about 2.5% of node capacity—well within normal housekeeping variance. This confirms that the act of querying cgroup pressure files and exposing them via the metrics endpoint is extremely lightweight, making it safe for even the most resource-constrained deployments.
7. System CPU Overhead: Small and Predictable
Beyond the Kubelet itself, the team also examined system-level CPU consumption. With kernel PSI tracking always active (since psi=1 is default on modern distributions), the incremental cost of Kubernetes reading those metrics is minimal. The test data showed that system CPU usage on PSI-enabled clusters ran slightly higher than the disabled baseline—a small, stable offset. At around 2.5 cores of system usage overall, the delta was barely noticeable. This predictable behavior means operators can confidently enable PSI without needing to budget for a surprise resource tax.
8. What This Means for Your Production Clusters
With PSI metrics now GA, you can start using them today for better alerting, scheduling decisions, and even autoscaling policies. Proactive detection of memory or I/O pressure becomes straightforward: set thresholds on the 10-second moving average and trigger warnings before tasks degrade. For debugging, the cumulative counters let you correlate stalled time with event logs. Since overhead is proven negligible, there's no downside to enabling PSI across your fleet. Upgrade to v1.36, update your monitoring dashboards, and let the pressure signals guide your next capacity or performance improvement.
The graduation of PSI to GA in Kubernetes v1.36 marks a pragmatic step forward for observable reliability. By giving cluster operators a direct line into resource contention without adding operational cost, this feature empowers teams to build more resilient, self-tuning infrastructure. Whether you're tuning node-level resource limits or debugging a mysterious latency spike, PSI provides the data you need—finally stable, always there.
Related Articles
- BleachBit Launches Interactive Text Interface for Headless Server Cleaning
- Critical Linux Kernel Flaw 'Dirty Frag' Exploited: New 'Killswitch' Proposed to Mitigate Vulnerabilities
- Fedora Linux 44 Now Available for Silverblue: Upgrade via GUI or Terminal with Rollback Safety
- Upgrading to Fedora Linux 44 on Silverblue: A Step-by-Step Q&A
- How to Adapt Your Fedora Atomic Desktop to Fedora Linux 44: Key Changes & Step-by-Step Guide
- Mastering Linux Security Updates: A Practical Guide for Multi-Distro Environments
- How to Test Sealed Bootable Images for Fedora Atomic Desktops: A Step-by-Step Guide
- How to Choose Your Server Location in Mozilla VPN for Firefox